Background
In modern applications, database availability is critical. Downtime means not just a loss in revenue but also user trust. This article outlines our journey in designing a highly available PostgreSQL architecture using:
– 5 PostgreSQL nodes (1 leader + 4 replicas)
– 2 HAProxy nodes with Keepalived for load balancing and virtual IP failover
– 5 Patroni nodes for PostgreSQL orchestration and automatic failover
– 3 etcd nodes as a distributed key-value store for Patroni coordination
We’ll walk through our rationale, challenges, and how each component solves a specific availability issue.
The Problem: Ensuring High Availability in PostgreSQL
PostgreSQL, while robust, does not provide built-in automatic failover. Our goal was to:
– Avoid single points of failure
– Automatically detect and handle PostgreSQL leader failures
– Minimize downtime during failovers
– Provide seamless traffic routing to the current leader node
Our earlier setup relied on manual failover scripts and DNS updates—slow, error-prone, and unsustainable in production environments.
Technology Selection Journey
After evaluating various solutions (e.g., Pacemaker/Corosync, repmgr), we chose the following stack:
– PostgreSQL: Core relational database engine
– Patroni: Manages PostgreSQL clustering, failover, and health checks
– etcd: Backend DCS (Distributed Configuration Store) for Patroni
– HAProxy: Load balancer that routes traffic to the current leader
– Keepalived: Adds high availability to HAProxy using Virtual IP
This stack gave us automated failover, dynamic leader election, and HA on both database and proxy layers.
Architecture Overview
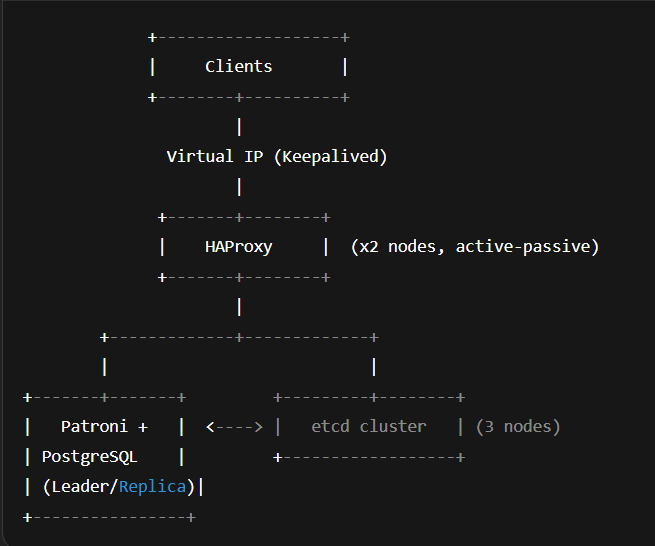
Key Points:
– Patroni runs on each PostgreSQL node and communicates with etcd.
– etcd holds the current state and leader election info.
– HAProxy checks etcd to determine the current leader and routes writes accordingly.
– Keepalived manages a floating virtual IP between the two HAProxy nodes.
HAProxy + Keepalived: High Availability at the Proxy Layer
Problem:
If the single HAProxy node failed, clients would lose access to PostgreSQL—even though the DB might still be running.
Solution:
We deployed 2 HAProxy nodes with Keepalived, which provides a floating virtual IP between them. Only the active node holds the VIP, and in case it goes down, the standby takes over immediately.
Features used:
– Health checks to determine if HAProxy is alive
– Keepalived priority/preempt settings for failback
Patroni + etcd: PostgreSQL Failover and Coordination
Problem:
PostgreSQL doesn’t natively support automatic failover or leader election.
Solution:
Patroni continuously monitors the PostgreSQL cluster and uses etcd to store cluster state and perform distributed consensus for leader election.
Why etcd?
– Highly consistent and fault-tolerant
– Simple key-value model that fits Patroni’s needs
– Actively maintained and production-ready
Failover Flow:
1. Patroni detects the leader is unresponsive.
2. Patroni checks etcd for consensus.
3. A new leader is elected.
4. HAProxy detects the change and reroutes traffic.
This takes just a few seconds.
Testing the Setup
We simulated various failure scenarios:
– Leader PostgreSQL down → Patroni promotes a new replica
– HAProxy node down → Keepalived fails over to standby
– etcd node down → Cluster continues as quorum exists
– Network partition → Patroni prevents split-brain via etcd quorum
Resilience Highlights
– Zero single points of failure
– Fast automatic failover (under 10s)
– No manual intervention required
– Seamless client redirection via HAProxy
Lessons Learned
– Patroni and etcd offer a simple, clean model for PostgreSQL HA.
– HAProxy + Keepalived adds another critical layer of availability.
– Monitoring is crucial to catch issues early.
– Ensure proper tuning for Patroni settings like ttl, loop_wait, and retry_timeout.
Final Thoughts
This setup has given us robust high availability for PostgreSQL in production. It scales, it recovers, and it gives us confidence that the database tier won’t be a bottleneck in our reliability stack.
Leave a Reply